
DevOps On A Dime for SMBS
You’re a small to medium-sized business in the US, and you’ve heard the whispers, perhaps the shouts, about “DevOps.” Maybe it sounds like something only the tech giants can afford, a luxury reserved for companies with endless budgets and armies of engineers. You’re thinking about the bottom line, the summer rush, and how to make every dollar stretch further. This is about making your tech work for you, efficiently, reliably, and without bleeding your finances dry.
The reality is, DevOps isn’t an exclusive club. It is a philosophy, a set of principles that, when applied thoughtfully, can radically transform your operations and, more importantly, your financial health. It is about building a better system, a more resilient one, a leaner one. And here’s the secret: you don’t need a multi-million-dollar budget to start. You need conviction, a willingness to iterate, and an understanding that small, consistent changes accumulate into monumental gains.
The Tyranny of the Manual
Every manual step in your software development and deployment process is a ticking financial liability. Think about it. That developer who spends half a day manually deploying an update? That’s not just their salary for those hours; it’s the opportunity cost of what they could have been building. The late-night scramble to fix a production bug caused by a human error during a release. That’s lost revenue, damaged customer trust, and the exhaustion of your team.
For SMBs, these hidden costs are magnified. You don’t have infinite resources to absorb inefficiencies. Every wasted minute, every avoidable error, every delayed feature release directly impacts your ability to compete, innovate, and serve your customers. This is where DevOps steps in, not as a mystical, complex paradigm, but as a practical path to financial liberation.
What are these hidden costs, really?
- Labor Costs from Repetitive Tasks: How much time do your developers or IT staff spend clicking buttons, copying files, configuring servers by hand, or running manual tests? Each of these tasks is prone to error, tedious, and consumes valuable, highly paid human capital that could be focused on innovation. This isn’t just about their hourly wage; it’s about the value they aren’t
- Downtime and Outage Costs: When your website goes down, your application glitches, or your internal tools fail, what’s the tangible impact? Lost sales, frustrated customers, damaged reputation, and frantic, expensive firefighting. For a small e-commerce business, even an hour of downtime can mean thousands in lost revenue. For a service provider, it means client dissatisfaction and potential contract loss.
- Reduced Time to Market: Every week, every day, every hour that a new feature or critical bug fix is delayed is a lost opportunity. It means your competitors might get there first, your customers might lose patience, or your internal teams might continue to struggle with inefficient tools. The velocity of your software delivery directly translates to your business’s agility and responsiveness.
- Quality Debt and Rework: Manual processes and rushed deployments lead to bugs. Bugs lead to rework. Rework is expensive. It consumes development cycles, requires more testing, and often disrupts other planned work. The cost of fixing a bug in production is exponentially higher than catching it during development. This “quality debt” compounds over time, draining resources.
- Security Vulnerabilities: Manual configurations are rarely consistent or secure. Overlooking a single firewall rule or misconfiguring an access policy can open your business to significant security risks, leading to data breaches, compliance fines, and reputational ruin. Proactive, automated security checks integrated into your development pipeline are not a luxury; they are a necessity.
- Burnout and Turnover: The constant firefighting, late nights, and stress associated with chaotic, manual IT operations take a toll on your team. Burnout leads to reduced productivity, increased errors, and ultimately, talented people walking out the door. Replacing and training new staff is incredibly expensive for an SMB.
DevOps, at its core, is an antidote to this tyranny. It’s about systematically dismantling these hidden costs by instilling collaboration, automation, and continuous improvement into the very fabric of your tech operations.
The Foundation
Before you even think about which open-source tools to download or which cloud service to subscribe to, let’s talk about the absolute bedrock of DevOps for any organization, especially an SMB: culture. This isn’t fluffy HR talk. This is about practical alignment and shared responsibility.
In many smaller businesses, “dev” (developers building software) and “ops” (the IT folks keeping the lights on) often exist in their own silos. Developers want to ship features fast; ops wants stability. These divergent goals, while understandable, create friction, blame, and ultimately, slow down everything.
DevOps aims to bridge this chasm. It is about:
- Shared Goals: Both development and operations teams need to work towards common business objectives: faster, more reliable software that delivers value to customers. Their incentives should align.
- Empathy and Collaboration: Developers need to understand the challenges of running software in production. Operations needs to understand the pressures of rapid development. Regular, open communication, shared dashboards, and joint problem-solving sessions are far more impactful than rigid handoffs.
- Blameless Post-Mortems: When things go wrong (and they will), the focus should be on what happened and how to prevent it in the future, not who caused it. Learning from failure is paramount for continuous improvement.
- Ownership Across the Lifecycle: Developers shouldn’t just “throw code over the wall.” They should feel a sense of ownership for their code even after it’s in production. Operations teams should be involved earlier in the development lifecycle, providing feedback on operational concerns.
This cultural shift doesn’t require a budget; it requires leadership and a willingness to facilitate conversations. Start small: bring your dev and ops leads together for a weekly sync. Encourage developers to join on-call rotations occasionally. Vice versa. Break down the “us vs. them” mentality.
Once the cultural seeds are sown, the tools become accelerators, not crutches. They amplify the positive effects of a collaborative environment.
Open Source and Cloud Native for SMBs
Now, for the practicalities. You need to automate, monitor, and streamline, but without breaking the bank. The good news is the open-source community and cloud providers have democratized many enterprise-grade capabilities, making them accessible and affordable for SMBs.
1. Version Control: Your Single Source of Truth
This isn’t optional; it’s foundational. Every line of code, every configuration file, every script should be in a version control system.
- Git: This distributed version control system is the industry standard for a reason: it’s free, powerful, and enables collaborative development.
- Cloud-Hosted Git Platforms: For team collaboration and added features, look at platforms with generous free tiers or affordable plans.
- GitHub: Widely popular, excellent for collaboration, integrated CI/CD (GitHub Actions, more on this later).
- GitLab: An all-in-one platform offering Git, CI/CD, project management, and more. Their self-managed option on a Linux server is powerful for privacy and cost control, while their cloud tier is also competitive.
- Bitbucket: Another solid option, particularly if you’re already in the Atlassian ecosystem (Jira, Confluence).
The financial gain: Eliminates “it works on my machine” issues, provides clear audit trails, enables easy rollbacks, and prevents lost work. This translates directly to less rework and faster recovery from errors.
2. Continuous Integration (CI): Catching Problems Early
CI is the practice of frequently merging code changes into a central repository, where automated builds and tests are run. The goal is to detect integration issues early, before they become complex and expensive to fix.
- Jenkins (Self-Hosted): The classic open-source CI/CD server. It’s free to use, highly extensible with thousands of plugins, and can run on a modest Linux server (even a low-cost AWS EC2 instance). The learning curve is moderate, but the community support is vast.
- Cloud-Native CI/CD (Free Tiers):
- GitHub Actions: If your code is on GitHub, Actions offers a powerful, integrated CI/CD solution with a generous free tier for public repositories and competitive pricing for private ones. It’s YAML-based, making it easy to define workflows.
- GitLab CI/CD: Similarly, if you’re on GitLab, their integrated CI/CD is robust, easy to configure with .gitlab-ci.yml files, and offers a good free tier.
- CircleCI: Known for its speed and simplicity, especially for mobile and web projects. Has a free tier.
- Basic Scripting: Don’t underestimate the power of simple shell scripts run via cron jobs initially, or basic build scripts that compile and run tests. You don’t need a full-blown CI server on day one for every single project.
The financial gain: Reduces the cost of bug fixes by catching them early in the development cycle. Faster feedback loops mean developers spend less time debugging complex integration problems.
3. Continuous Delivery/Deployment (CD): Automated Releases
This is where the magic happens: automating the release of your software to production. This dramatically reduces manual errors, speeds up deployments, and frees up your team.
- Integrated CI/CD Platforms: The same tools mentioned for CI (GitHub Actions, GitLab CI/CD, Jenkins) often handle CD as well. You define pipeline stages that build, test, and then deploy to various environments (staging, production).
- Ansible / Puppet / Chef (for Configuration Management): While these can be complex for a small team, Ansible is particularly accessible due to its agentless nature and YAML-based playbooks. It’s excellent for automating server setup, application deployments, and configuration updates. Puppet and Chef are more robust for larger, more complex infrastructures, but might be overkill initially.
- Containerization (Docker): Packaging your application into Docker containers ensures consistency across environments. A Docker image built in development will run identically in testing and production. This eliminates “dependency hell” and simplifies deployment. Docker Desktop is free for small teams, and running containers on a Linux server is straightforward.
- AWS Services for Deployment: If you’re on AWS (and many SMBs are), consider services like:
- AWS CodeDeploy: Automates software deployments to various compute services (EC2, Lambda, ECS).
- AWS Elastic Beanstalk: A higher-level service that makes it easy to deploy and scale web applications and services. It handles underlying infrastructure provisioning and management.
- AWS Fargate (with ECS/EKS): For serverless containers. You pay only for the compute resources your containers use, without managing servers.
The financial gain: Eliminates manual deployment errors, significantly reduces downtime during releases, accelerates time to market for new features and bug fixes, and allows for more frequent, smaller, less risky deployments.
4. Monitoring and Observability: Knowing What’s Happening
You can’t fix what you don’t see. Robust monitoring helps you understand the health and performance of your applications and infrastructure, allowing you to proactively address issues before they impact customers.
- Prometheus + Grafana (Open Source): A powerful combination for collecting, storing, and visualizing metrics. Prometheus scrapes metrics from your applications and infrastructure, and Grafana provides beautiful, customizable dashboards. Both are free and have extensive communities.
- ELK Stack (Elasticsearch, Logstash, Kibana – Open Source): For centralized logging. Logstash collects logs from various sources, Elasticsearch stores and indexes them, and Kibana provides a powerful interface for searching, analyzing, and visualizing log data.
- AWS CloudWatch: For AWS users, CloudWatch is the native monitoring service. It collects logs, metrics, and events from all your AWS resources. You can set alarms, create dashboards, and integrate with other services. Costs are usage-based, but often very reasonable for SMBs.
- UptimeRobot (Free Tier): A simple, external monitoring service that checks if your website or API is up and sends alerts if it’s down. A basic free tier is available.
The financial gain: Proactive problem-solving reduces the impact and cost of outages. Faster root cause analysis minimizes downtime. Identifying performance bottlenecks allows you to optimize resource usage and defer unnecessary infrastructure upgrades.
5. Infrastructure as Code (IaC): Repeatable Environments
Defining your infrastructure in code (e.g., a text file) means you can version control it, reuse it, and provision environments consistently and automatically.
- Terraform (Open Source): A cloud-agnostic IaC tool that allows you to define and provision infrastructure across various cloud providers (AWS, Azure, GCP) using a declarative language.
- AWS CloudFormation: AWS’s native IaC service. It allows you to model and provision all your AWS resources using templates.
The financial gain: Eliminates manual configuration errors, ensures consistency across environments (dev, test, prod), speeds up environment provisioning, and simplifies disaster recovery. This directly reduces manual labor and improves system reliability.
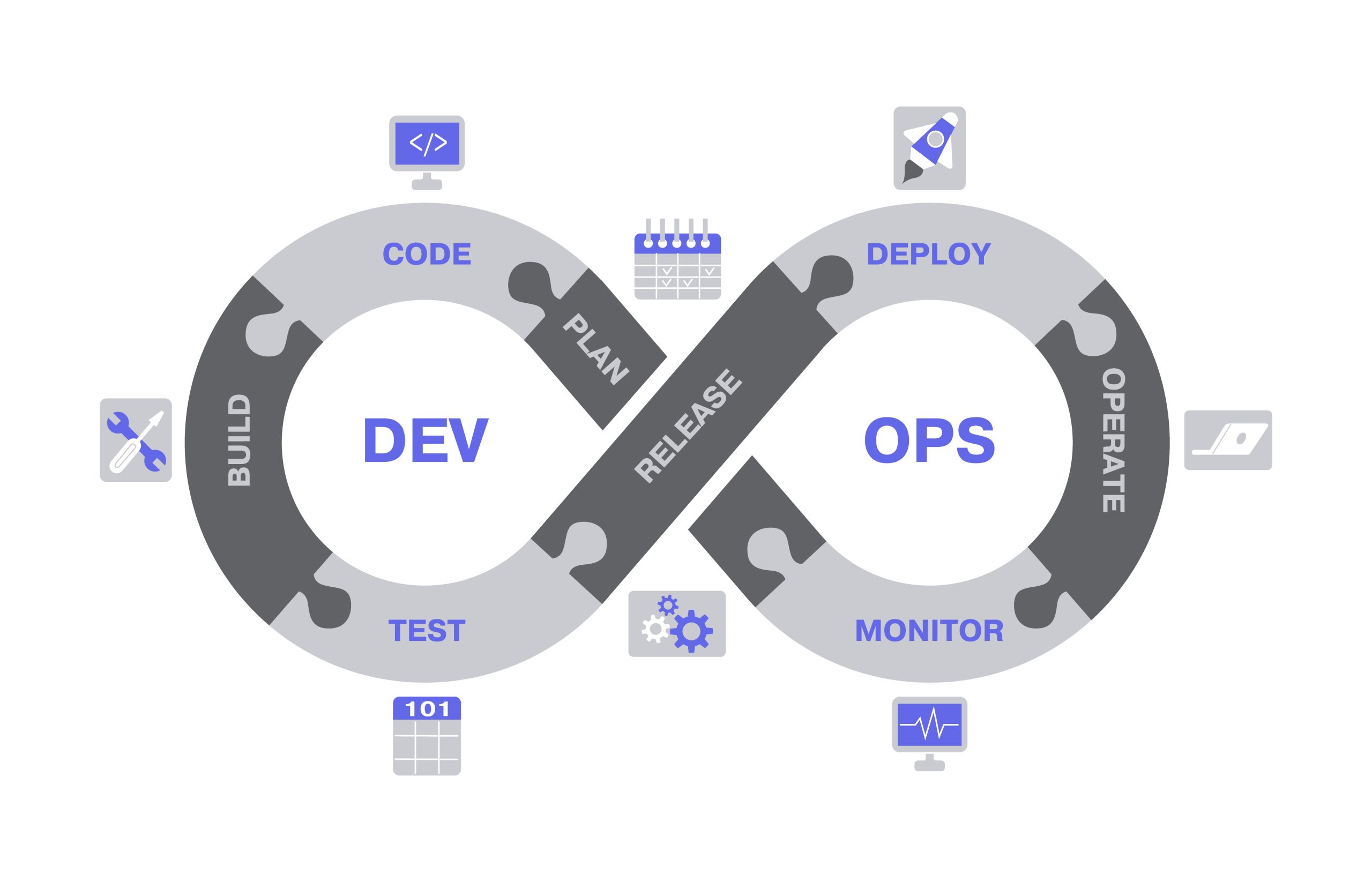
DevOps scheme, software development lifecycle operations concept. Software engineering workflow cycle vector illustration. DevOps software development process. Information technology engineering
You Don’t Have to Do It All at Once
The biggest mistake an SMB can make when approaching DevOps is trying to implement everything at once. This leads to overwhelm, frustration, and eventual abandonment. Instead, think incrementally. Each step should deliver tangible value, building momentum and making the next step easier.
Here’s an incremental roadmap, focusing on immediate financial and operational wins:
Phase 1: Get Your House in Order (Weeks 1-4)
- Step 1: Version Control Everything. Start by ensuring all application code, configuration files, and critical scripts are in a Git repository (GitHub, GitLab, Bitbucket). This is non-negotiable.
- Step 2: Basic Centralized Logging. Even if it’s just pushing application logs to AWS CloudWatch Logs or a simple ELK stack, get visibility. You can’t fix what you don’t see.
- Step 3: Simple Uptime Monitoring. Set up UptimeRobot or a basic CloudWatch alarm for your critical application endpoints. Know immediately when something breaks.
- Financial Impact: Reduced manual errors, quicker identification of issues, initial understanding of current state. Low cost, high impact.
Phase 2: Automate the Basics (Months 2-3)
- Step 4: Automate Your Build Process (CI). Set up a basic CI pipeline (using GitHub Actions, GitLab CI/CD, or a self-hosted Jenkins instance on a small Linux VM) that automatically compiles your code and runs basic unit tests every time a developer commits changes.
- Step 5: Automate Test Environment Provisioning. Can you spin up a clean test environment (even a simple one) using a script or basic IaC (CloudFormation/Terraform) instead of manual setup? Focus on one application first.
- Financial Impact: Faster feedback to developers (reducing rework), consistent build processes, less time spent manually preparing test environments. Starts to free up developer time.
Phase 3: Streamline Releases (Months 4-6)
- Step 6: Automate Your Staging Deployment (CD to Staging). Extend your CI pipeline to automatically deploy successful builds to a staging environment. This is a big step towards “push-button” deployments.
- Step 7: Basic Configuration Management. Use Ansible playbooks to standardize the setup of your application servers in staging. This ensures consistency.
- Step 8: Dockerize One Application. Pick a single application and containerize it. Learn the process. This sets the stage for more robust deployments.
- Financial Impact: Reduced manual deployment errors to staging, faster iteration on features, ability to test deployments more reliably. Direct reduction in deployment-related toil.
Phase 4: Optimize and Scale (Months 7-12 and Beyond)
- Step 9: Automated Production Deployment (CD to Production). This is the ultimate goal. Implement a robust CD pipeline for your most critical application. This might involve blue/green deployments or canary releases for minimal downtime.
- Step 10: Deeper Monitoring and Metrics. Expand your Prometheus/Grafana or CloudWatch dashboards to include more granular application metrics (e.g., request latency, error rates, database query times). Set up actionable alerts.
- Step 11: Embrace Infrastructure as Code (IaC) More Widely. Start defining more of your infrastructure (databases, networking, other services) as code.
- Step 12: Explore Serverless and Managed Services. For new features or applications, evaluate if AWS Lambda, AWS Fargate, or managed databases (RDS, DynamoDB) offer better price/performance and reduced operational overhead.
- Financial Impact: Maximize uptime, minimal deployment risk, highly efficient resource utilization, proactive problem-solving, continuous improvement in TCO. This is where the long-term, compounding financial benefits truly manifest.
This incremental approach allows you to learn, adapt, and demonstrate value at each step. You’re not making massive, risky investments upfront. You’re building capability and confidence, one financially sensible step at a time.
The Long-Term Financial Horizon
The true power of DevOps for an SMB isn’t in a single, dramatic cost reduction. It is in the compounding effect of continuous improvements over time. Think of it like investing: consistent, small contributions, when compounded, yield exponential returns.
- Sustained Cost Reduction: By eliminating manual tasks, reducing errors, and optimizing resource utilization through automation and smart architecture, your operational costs will steadily decline. This isn’t a one-time saving; it’s a structural improvement in your cost base.
- Increased Velocity and Innovation: Faster, more reliable releases mean you can bring new products, services, and features to market more quickly. This translates directly to increased revenue opportunities, enhanced competitiveness, and a better ability to respond to market shifts.
- Improved Quality and Customer Satisfaction: Fewer bugs, less downtime, and more consistent performance mean happier customers. Happy customers are loyal customers, who are more likely to recommend your business, leading to organic growth and reduced customer acquisition costs.
- Enhanced Security Posture: Integrating security practices throughout your development pipeline (DevSecOps) from the outset is far less expensive than reacting to a breach after it occurs. Automated security scans, consistent configurations, and rapid patching minimize your risk and protect your reputation.
- Better Employee Morale and Retention: A streamlined, automated environment reduces stress, eliminates tedious work, and allows your technical talent to focus on challenging, meaningful problems. This leads to higher job satisfaction, reduced burnout, and lower employee turnover, saving significant recruitment and training costs.
- Scalability for Growth: A well-architected DevOps pipeline allows your business to scale more easily without exponentially increasing IT staff or infrastructure costs. As your business grows, your efficient processes can handle the increased load with relative ease. This is critical for seizing opportunities.
- Reduced Risk Profile: By automating processes, continuously monitoring, and having robust feedback loops, you reduce the overall risk associated with your technology operations. This means less vulnerability to human error, security breaches, and catastrophic outages.
DevOps on a dime is how you not only survive but thrive in a landscape where software defines success, and every dollar must work harder. The investments you make in this approach today will pay dividends, not just in technical performance, but directly on your financial statements, for years to come.