Accelerate the Launch of New Digital Banking Propositions with Platea from NTT DATA
 |
| NTT DATA |
 |
Platea Banking is a digital banking solution developed by NTT DATA to be used by clients as an accelerator in their modernization journeys, especially when creating a new banking platform.
Platea is positioned as a modernization vehicle that provides a ready-to-go digital infrastructure and architecture over both internal and external components as core. It includes pre-built functional modules and integrations with a third-party ecosystem, with Mambu at its heart as a core engine.
Platea accelerates the modernization journey by reducing time to market and providing a future-proof technology, avoiding vendor lock-in, and setting clients in the driver’s seat with autonomy and full control.
In this post, we will learn how Platea Banking architecture is designed to provide a next-generation digital architecture to support the most challenging business ventures:
- Cloud-native platform with hybrid capabilities.
- Data and event-driven real-time architecture (EDA).
- Double API management approach that separates exposure to third parties from the connectivity to third-party APIs.
- API-first design, using domain-driven design and hypermodular techniques for business-as-a-service modules.
- End-to-end automated DevSecOps platform for complete business delivery.
NTT DATA is an AWS Advanced Tier Services Partner and Managed Services Provider (MSP) that supports clients in their digital development through a wide range of services.
The Customer Need
Major banks and financial institutions once had their core workloads in mainframes. Mainframes were a success back in the day due to their reliability, computing power, and transactionality. Organizations today face challenges of defining and implementing production digital solutions in record time to be competitive.
Apart from the mainframe capabilities, businesses require additional IT features, including elasticity and pay-as-you-go pricing, real-time interaction, value delivery, and information management. The bank’s system also becomes more complex due to the increasing number of components that compose it, as well as the additional requirements that arise from reliability requirements and system operation.
From this new digital paradigm, the idea of creating a digital solutions platform capable of supporting exponential businesses arose.
The Solution
Due to the need of creating a robust and scalable platform, which solves global banking business use cases, NTT DATA aimed to get a reactive architecture in Platea. This is defined by four main features which are detailed in the Reactive Manifesto:
- Responsiveness
- Resilience
- Elastic
- Message Driven
This kind of architecture fits perfectly with Platea requirements because it allows high availability and dynamic scaling based on the workload, while guaranteeing a response on each part of the system in a decoupled way, thus optimizing the dedicated resources.
However, a pure reactive architecture is not enough. It’s necessary to support synchronous interactions due to the fact many software-as-a-service (SaaS) solutions have standard http APIs (typically REST APIs) which are not message-driven. The exposed interface mostly needs to be via REST APIs to enable interaction with other systems which interact with the Platea open banking solution.
Domain-Driven Design
The domain-driven design pattern is set as the basis for the decomposition of functionalities in the Platea system and, thus, the services definition. More than a design pattern, it’s an approach to software development for complex needs by connecting the implementation to an evolving model.
Event-Driven Architecture
In contrast to a message-driven system, in which a message is an item of data that is sent to a specific destination, an event is a signal emitted by a component upon reaching a given state. Event-driven architecture promotes the production, detection, consumption, and reaction to events.
Basically, each service publishes an event whenever it updates its data; meanwhile, other services subscribe to events. When an event is received, a service updates its data.
When a service performs an operation inside a distributed transaction, the events are generated once the transaction is committed (the update is committed when the transaction is committed, even if the data itself is updated before that). In cases when the transaction is cancelled, no event is generated, despite there being at least two changes in the data (change and rollback).
Among the benefits is the possibility of developing loosely-coupled microservices that improve elasticity and are able to scale independently. Finally, the use of this architecture fits with the event sourcing pattern described below.
Event Sourcing Pattern
The fundamental idea in the event sourcing pattern is that every change in the state of an application entity must be captured in an event object. These event objects are themselves stored in the sequence they were created for the lifetime of the application state itself.
Saving an event in a single operation is an atomic operation. Every command executed in the system will produce one or more events if their underneath actions have been executed successfully. This means the event store is the source of truth for the whole architecture of the system, being able to reconstruct an entity current state by replaying the events. This is a key factor to cover audit needs.
With the objectives of improving the observability and auditing the system, the events and errors will be recorded so the system can ingest it and have the information of everything that happened at each precise moment. This provides a 100% reliable audit log of the changes made to a business entity, as well as all the events that happened in the system.
In Platea, event sourcing is forbidden as a distributed transaction communication. The transaction manager is responsible for generating events once the transaction is finished successfully (committed).
The generated events also serve to communicate the command side and query side microservices developed with the CQRS pattern described below.
Benefits of event sourcing:
- Enables a 100% reliable audit log on entity modifications.
- Allows entity state searches at any specify date back in time.
- Business logic is based on loosely-coupled entities interchanging events.
CQRS Pattern
The core concept of the command and query responsibility segregation (CQRS) pattern is that different models for updating and reading information can be used, which will be referred to in this post as the command and query parts, respectively.
Implementation is separated into two sides: one for commands and one for queries. This allows better scalability of the solution as each can be dimensioned separately. The command side is oriented to transactional operations, while the query is oriented to pure read-only services.
The model of the command and query may be different (and will be in many cases). The model of the command must be oriented to the transactional needs, while the model of the query is oriented only to the queries it may receive.

Figure 1 – Typical Platea microservices in CQRS cases.
Command Side Responsibilities
All the commands in the model must cover:
- Validation of the actions that are triggered by the users, including business restrictions.
- Data versioning maintenance, handling transactions and consistency.
- Atomicity of the exposed operations (from the point of view of the caller).
- Division of the requests into tasks and its coordination.
- Storage in the event journal of all the results of the execution of the commands.
Of course, it must deal and implement all the business logic of its domain.
Query Side Responsibilities
The query side creates a projection of all views necessary for the different clients of the system, like the traditional materialized views. This side will be responsible for:
- Keeping only the latest version of the data, according to how it is consumed.
- Data must be updated whenever there’s an update on the command side.
- Offer fast and reliable access to the data (high availability reads).
- Offer consistent access to the data (high consistency reads).
Apart from that, the query side must perform the necessary aggregations of the data so it gets enriched before serving it to the clients, thus increasing its value.
Communication Between Command and Query
Communication between commands and queries is carried out by an event broker, which allows decoupling from each other and improves scalability. The use of this type of communication system also provides responsiveness to the whole solution even if the system goes down, because the messages persist in the broker’s queue until they are consumed.
Despite adding a bit of latency, asynchronous communication provides responsiveness and resilience to the system.
Transactionality
The transaction manager is the architecture component in charge of managing distributed transactions among the Platea banking microservices architecture. It ensures atomicity, consistency, isolation, and durability (ACID), executes automatic rollbacks, including third-party products through configuration and automated event sourcing. Moreover, it is codeless for developers.
Platea Banking Architecture
The high-level architecture diagram below represents the main components of the Platea open banking platform and its communication model among different actors.
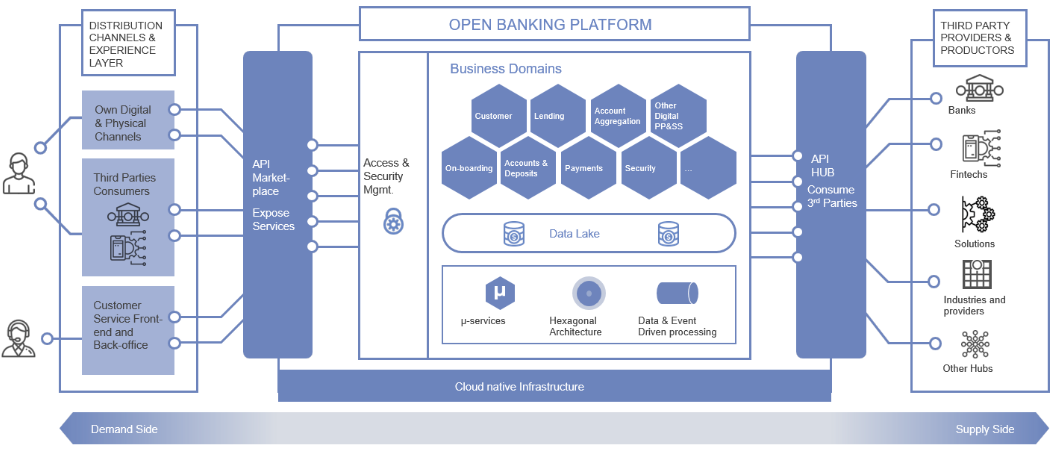
Figure 2 – High-level view of Platea architecture.
Infrastructure
The infrastructure system of Platea is based on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster as the main infrastructure component. Satellite systems are used to complement its functionality, including load balancers, network address translation (NAT) gateways, Amazon Route 53 domain name system (DNS) resolvers, network access control lists (NACLs), and security groups.
Most of the functionality lives in the EKS cluster as Kubernetes (K8s) objects. The orchestration, security, traceability, and observability of the cluster and objects is done using the Istio service mesh.
For relational data storage, there’s a multi-node private fully managed Amazon Aurora PostgreSQL cluster.
An Elasticsearch cluster has been provisioned for timeseries and object data storage. This is a managed standalone multi-node cluster living in the private subnets of the virtual private cloud (VPC).
An AWS-managed Kafka cluster is used as a message broker and transformation service along with the Logstash and Filebeat services running on Amazon EKS. There are also some AWS Lambda functions involved in the events, messages, and logs forwarding and manipulation.
Kong is part of the infrastructure and is deployed from AWS Marketplace. It’s used as an API manager and sits between load balancers, forwarding traffic to specific services in EKS.
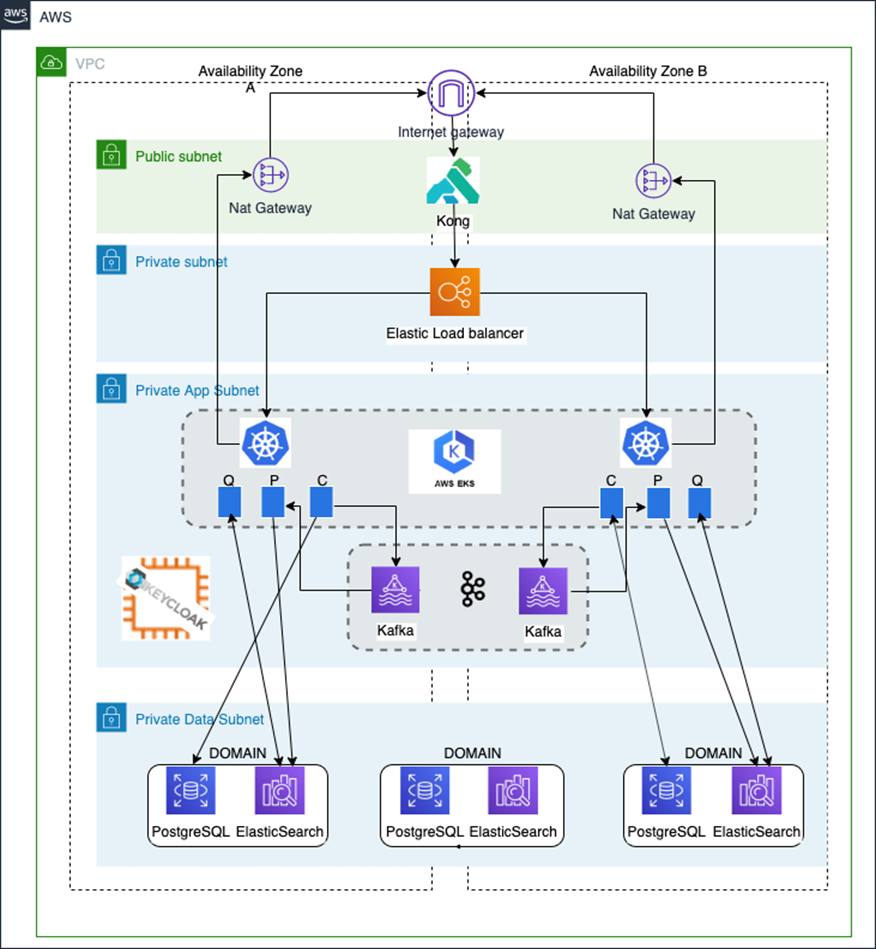
Figure 3 – Platea infrastructure.
Components Communication
The allowed communications between components models are different between cases.
Exposed Services
Services exposed to the outside are exposed through REST APIs. Components exposing services to the outside must support synchronous JSON-based REST calls.
Exposed Query Services
Components exposing query services should only call its data repository; they should not call any other components unless requirements make it impossible to avoid it.
Calls to External Components
Calls to external components will depend on technologies such as external components support. It’s expected to be done through HTTP calls (mainly REST calls).
Calls Inside Transactions in Command Side
There are two supported models for communication in command side:
- HTTP REST calls, for synchronous request-response communication.
- Kafka messaging, for both synchronous request-response communication over an asynchronous channel, and pure fire-and-forget messaging on a message-driven model.
Each command service may expose its synchronous services through any of these models, or through both. Asynchronous services should be exposed through the Kafka interface.
Any transaction may mix any type of calls between the services it needs to be completed.
Due to the nature of the transactions (specifically atomicity), a transaction which includes fire-and-forget calls cannot be committed until all of the processing has ended; however, any intermediate service is not aware of that.
General Model
Communication between components should be event-driven. That includes business events like changes due to transactions, as well as other types like observability alerts.
Any component may generate events and any component may listen to any events it can see. Events may be domain-scoped if required, so no component outside its domain can see it.
DevOps
A project with this scope requires a high level of deployment automation. The whole CI/CD system is based on AWS CodeCommit, AWS CodePipeline, AWS CodeBuild, FluxCD, and is triggered by Git.
The only action taken by the DevOps team is the promotion between environments, which is also an automated action based on Helm templates and the CI/CD tools.
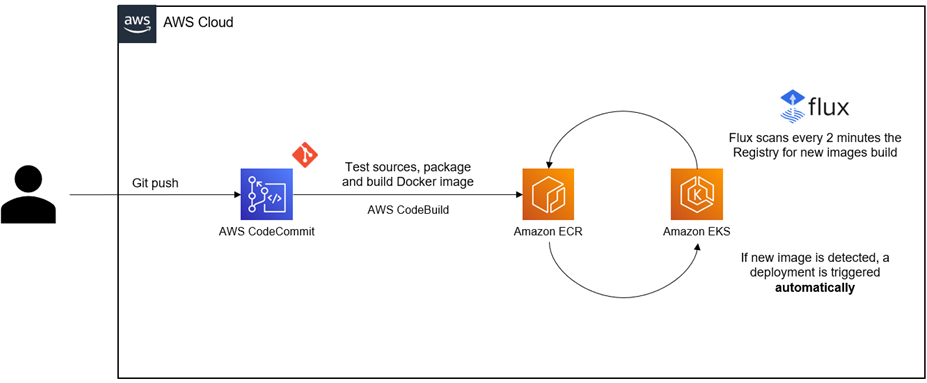
Figure 4 – Development and deployment flow.
The whole system is deployed in several non-prod and one production environment, allowing users to fully test the platform before pushing changes to production. Also, due to the nature of Docker and Kubernetes, rollbacks are easy to perform if needed.
The relational data is regularly “point in time” backed up; it’s also possible to be rebuilt from any point in time thanks to the immutable events stored.
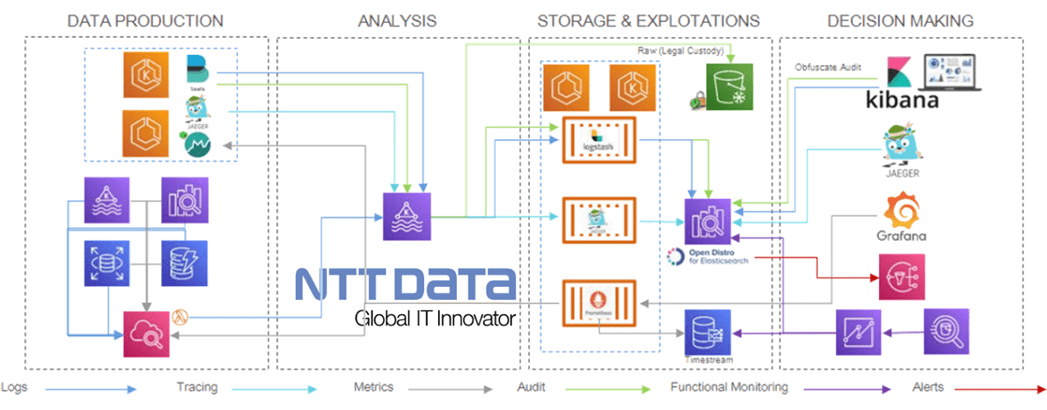
Observability
All components will be monitored using the following open-source stack:
- Jaeger
- Prometheus
- Grafana
- ELK (Elasticsearch, Logstash, and Kibana)
Prometheus scrapes metrics, both from applications and infrastructure, although the latter requires specific Prometheus exporters to obtain the information from Amazon CloudWatch. Thus, each EKS cluster will have its own Prometheus server for scrapping, as well as a Grafana instance for the visualization of the metrics.
Jaeger provides open tracing capabilities. Thus, each microservice must include the Jaeger library with which to trace the requests and send information to a Jaeger collector placed in a specific Kubernetes observability cluster.
Filebeat is the agent in charge of collecting the application and audit logs from EKS, while infrastructure logs will be collected from CloudWatch using a Lambda function which sends all the logs to Kafka. This way, you can observe the whole application as well as the infrastructure.
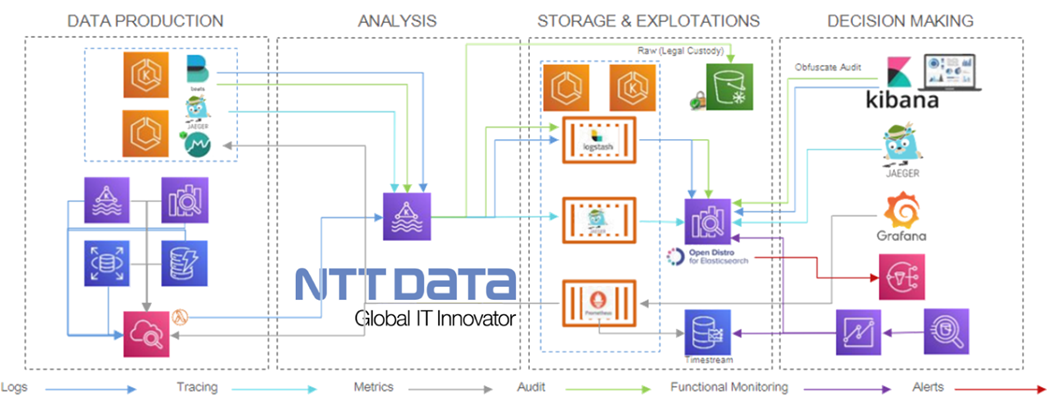
Figure 5 – Observability flow.
Applications
- Logging: A Filebeat agent is used for logs collection, and Logstash is used for aggregation and processing. These logs are previously stored in a Kafka topic to prevent overloading Logstash and to be consumed by the informational system. Finally, data is stored on Elasticsearch and visualized by users through Kibana.
- Monitoring: Prometheus is used for metrics collection and storage. Microservices must expose metrics with the Micrometer library; JVM metrics are essential to identify malfunctions or bottlenecks. Grafana is used for visualization, and data is stored in an external data storage system so it can be used for functional monitoring.
- Tracing: Jaeger is used for tracing collection and processing. Traces are also stored in a Kafka topic for the same reasons that logs are. Finally, data is stored on Elasticsearch and visualization is done via Jaeger user interface (UI).
Infrastructure
- Logging: A Lambda function collects the logs from CloudWatch and sends them to Logstash for aggregation and processing. These logs are also stored in Kafka so they can be consumed by the informational system. Eventually, the data will be stored on an Elasticsearch and visualized by users using Kibana.
- Monitoring: Prometheus is used for metrics collection and storage. An Elasticsearch-Kafka-Amazon RDS-CloudWatch exporter is required to expose database metrics. Visualization is done using Grafana. Here as well, data is stored in an external data storage system for further use in functional monitoring.
Conclusion
Creating a baseline for a banking application is a massive task that should not be done from scratch. Taking advantage of a mature, well-tested CQRS banking platform that can pass the regulators’ audits is a major advantage.
To deploy the solution on AWS using a fully automated orchestration system is a recipe for success. AWS is constantly maintaining and improving its services, regions, and data centers, so the growing need of a banking application is no challenge for the AWS infrastructure capability, which is resilient, secure, and certified.